Scansnapなどでスキャンした本・書類をPDFにした場合*、グレースケール・フルカラーなどでは、薄く読み取られ、文字が読みにくい場合があります。
*これは複数の画像がPDFというひとつの袋に入っているイメージです。
特に自炊をして、もうどこでも本が読めて部屋も広くなる!と思っていたのにいざscansnapで電子化したら画像が薄くて不満だって方は悲しすぎます。
そこで、その薄くて読みにくいPDFやscansnapで読み取ったデータを一括で濃くする方法を試しましたのでメモとして記載します。
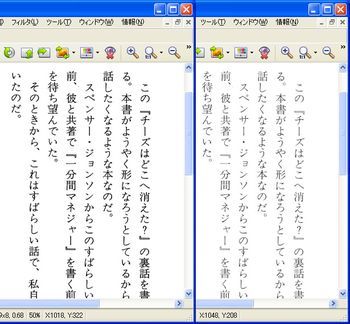
画像の右側の薄いPDFがscansnapのグレースケールくっきりモードで読み取った画像で、左側が変換後の濃くした画像です。
下記に詳しく書きますが、流れとしては「PDFから画像に一度戻し、画像ソフトで濃さを調整して、再びPDFに戻す」という手順*です。
*カラー・グレースケールで、薄くスキャンされてしまうことがあらかじめ予想される場合は、スキャン時に初めからjpeg出力しておくとPDFから画像の変換作業が省けて便利です。
色が薄い文字(本・書類をスキャンした)画像を濃くする手順
PDFから画像データの吐き出し
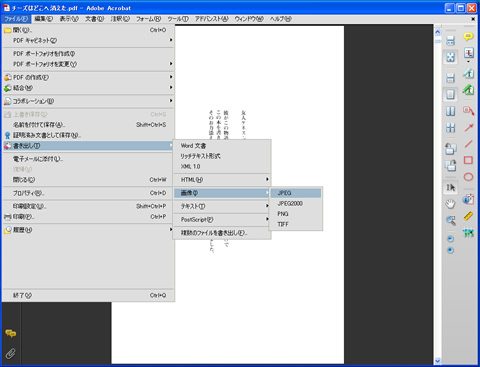
対象PDFをAcrobatで開き、メニューバーから「ファイル→書き出し→画像→jpeg」で吐き出します。
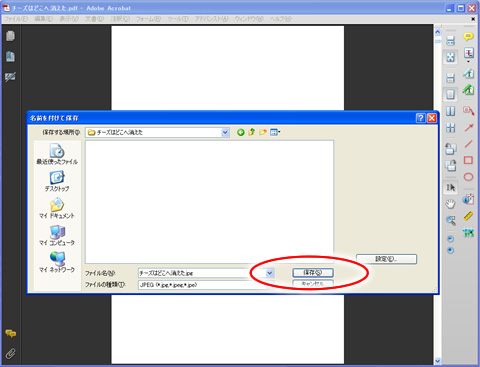
ファイル保存先を指定したら、「保存」ボタンを押します。するとPDFのページ分一気に画像が書き出されます。
画像ソフトで画像を濃くします
画像ソフトなんでもいいのですが、「コントラスト、明るさなど」の調整、バッチ処理(複数の画像ファイルに対して明るさなど変更する作業を自動で行ってくれる機能)が出来ることを考えると、有料ではPhotoshop/Fireworks、フリーソフトではXnViewあたりがいいと思います。ここではフリーソフトのXnView*で話を進めます。
* XnViewについては下記サイトを参考ください。
窓の杜 XnView
http://www.forest.impress.co.jp/lib/pic/piccam/picviewer/xnview.html
Wikipedia XnView
http://ja.wikipedia.org/wiki/XnView
まず、自分の好みの濃さを求める
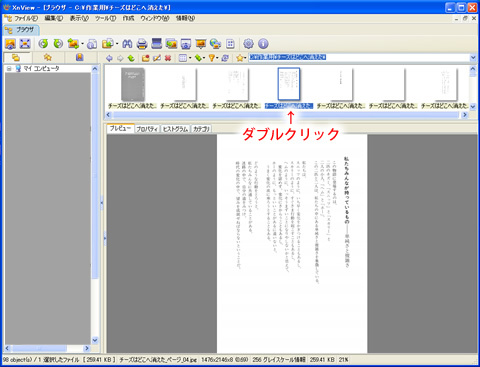
XnViewを起動するとファイル選択画面になるので、先程吐き出した画像フォルダを選択し、どれか画像をクリックします。
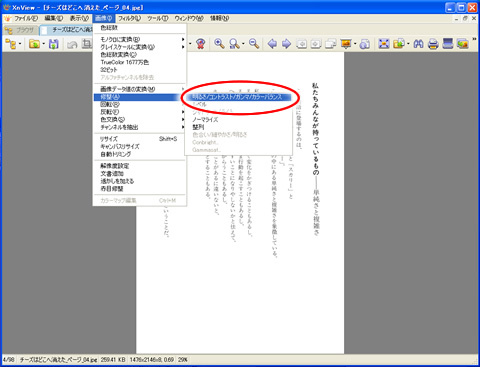
選択した画像が大きく表示されます。このモードで、メニューバーの「画像→修正→明るさ/コントラスト/ガンマ/カラーバランス」を選択します。
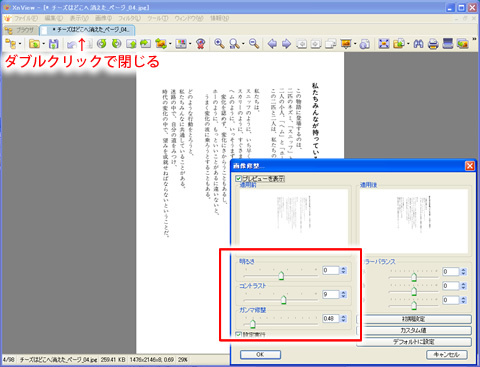
画像修正パネルが出ますので、コントラスト、ガンマなどをいじって自分の好みの濃さを割り出し、各数字をメモします。各数字をいじると、リアルタイムで画像が反映されますので、画像を見ながらいじるといいと思います。
この例では、明るさを0、コントラストを9、ガンマ修整を0.48で指定。
メモをしたらキャンセルで閉じて、上のタブをダブルクリックするとさらにこの編集画面が閉じられ起動時の画面に戻ります。
全ての画像に対して濃さを変更する
一枚ごとに先程の濃さの変更は大変なので、全ての画像に対して指定した濃さの変更を自動で行います(Photoshop/Fireworksではバッチ/コマンド処理というものです)。
メニューバーの「ツール→一括変換」を選択します。
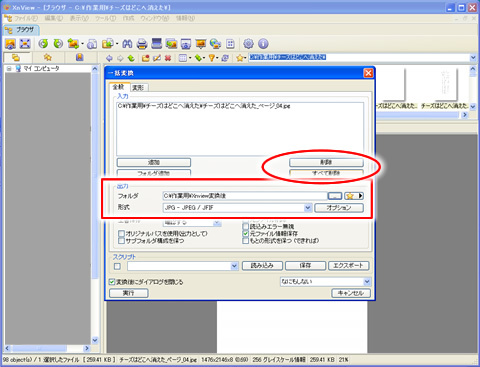
先程開いたファイルがひとつリストに入ってしまっていると思うので、ある場合は一度削除します。さらにその下にある、変換後のファイル出力先と、出力するファイル形式(jpegを指定)の指定を行います。
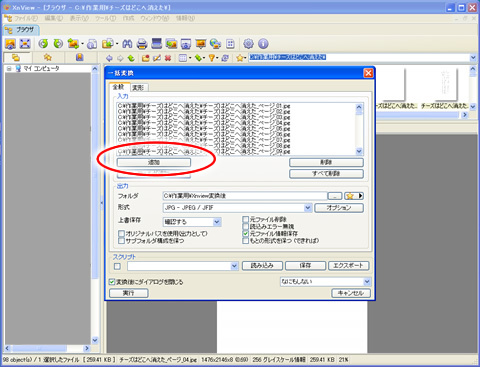
フォルダーの追加ボタンを押下し、先程PDFから吐き出した画像フォルダを選択すると、画像のように全てのファイルが選択されます。
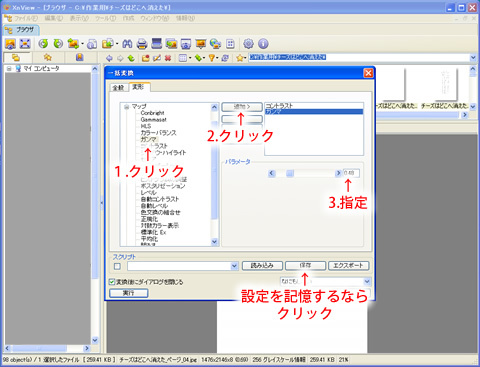
次に、「変形」のタブをクリックして、指定した画像に対して先程調べた明るさ、コントラストの指定を行います。
左側のコマンドリスト内のマップの項目にコントラスト、ガンマの項目があるので、項目を選択し追加を押すと、右側の実行リストに追加されるので、パラメーターに先程メモした数値を入力します。
もし、今後同じように画像を濃くする作業を行う場合は、スクリプトの項目で保存ボタンを押すと次回からこの入力作業しなくて済みます(次回はスクリプト欄から今付けた名前を選択するだけでコントラストなど各数値が呼び出せる)。
ちなみに、コマンドリスト内には画像のトリミング機能などもあるので、興味ある方は検証してみてください。
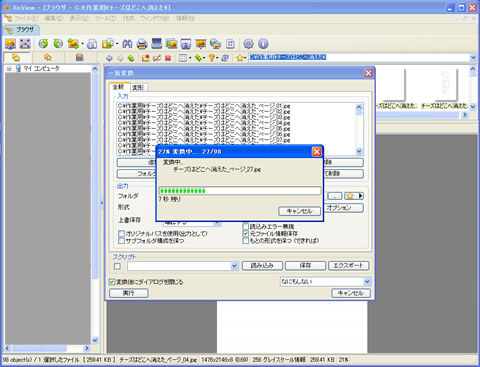
変換は最近のパソコンでしたら1~2分程度で終わります。
濃さを変更した画像の確認を行います
先程指定した変換後のファイル保存場所に変換した画像が出来てますので、画像を確認します。
図や写真が含むページでは微妙に濃い・薄いなどが出てくる場合がありますので、そのようの画像は個別で手動で調整し直します。
PDFに戻します
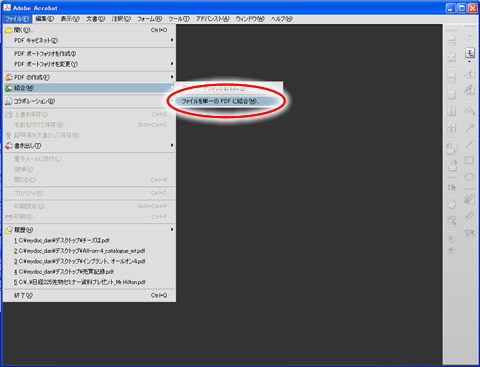
Acrobatのメニューバーから「ファイル→結合→ファイルを単一のPDFに結合→ファイルを追加(→フォルダを追加)」で結合します。
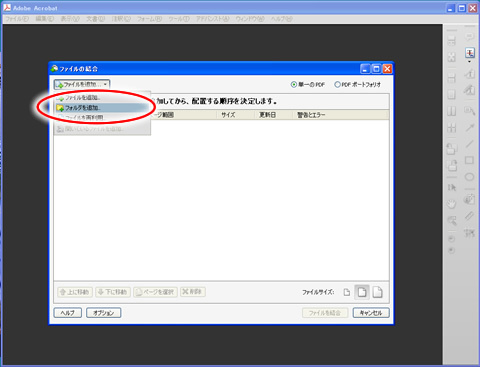
フォルダの追加を選択します。
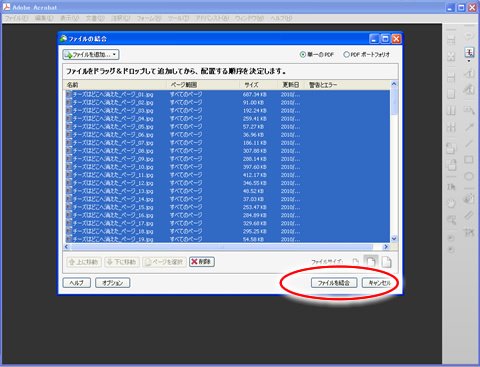
フォルダにある画像がすべて読み込まれました。デフォルトでは、画像1枚毎のファイル名がしおりとして入る設定になっているので、邪魔だと思う人は、「オプションボタン→常にPDFファイルにしおりを追加する」のチェックを外すといいと思います。
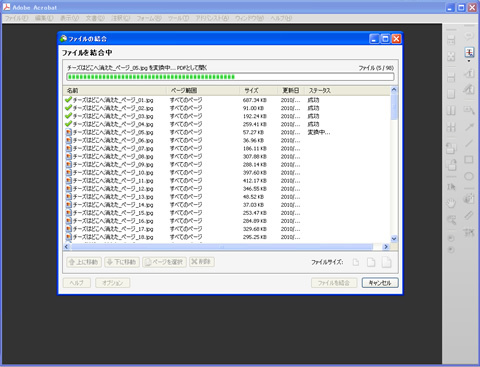
こんな感じで変換されます。大体1ページ0.5秒程度の速度で変換されます。
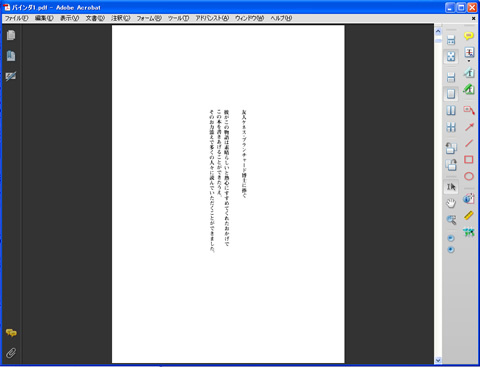
これで、薄い文字(スキャン画像)のPDFが濃くなって見やすくなります。後は、必要に応じてOCRをかけて文字認識をさせPDFを保存して完了です。
関連記事