PDFで収録されている文章・書類が、画像データなのか、文字(テキスト)データなのか判断する方法を紹介します。
ここでは、Windows PC・パソコン版のAcrobatで説明していきます。Macの方はご自身の画面と置き換えてご覧ください。
一見、同じ書類・文章ファイルでも保存されている種類が違うことがあります。例えば、、、
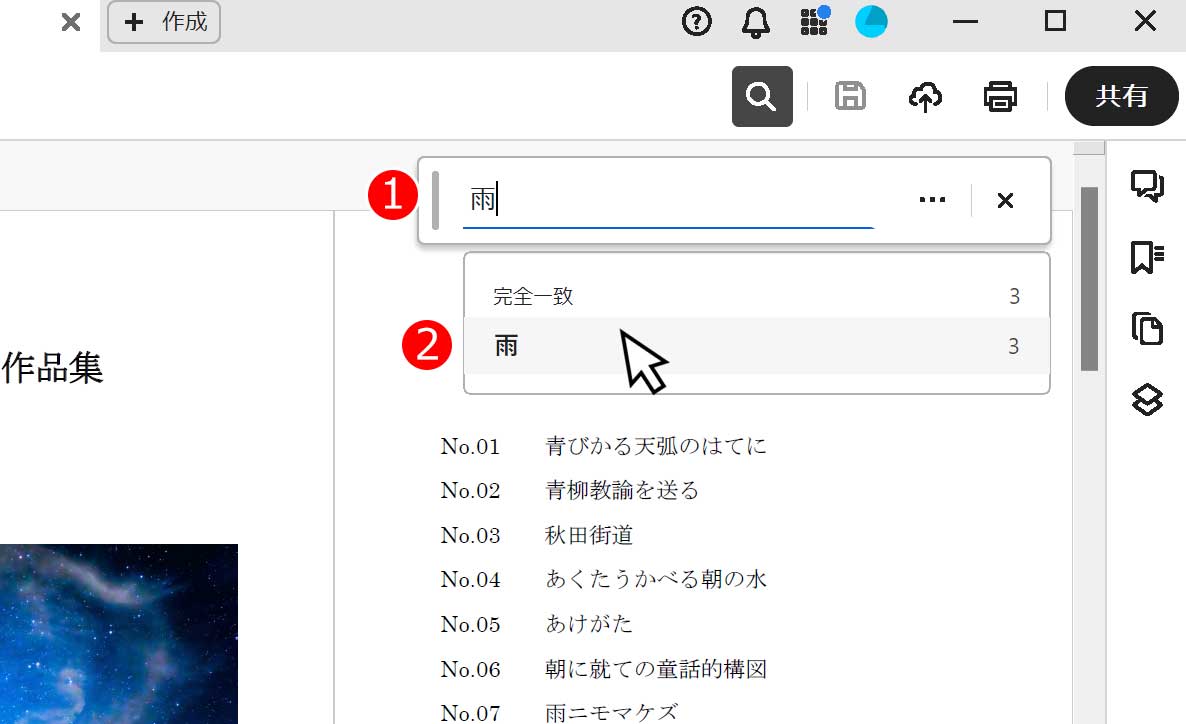
左がスキャンした(画像)のPDF、右がテキストデータで保存されているPDFです。文字の薄さなどに違いが出てますが、見慣れていない人は、ぱっと見て判断が付かないと思います。
PDFがスキャン画像か文字データで作られているか判断する方法
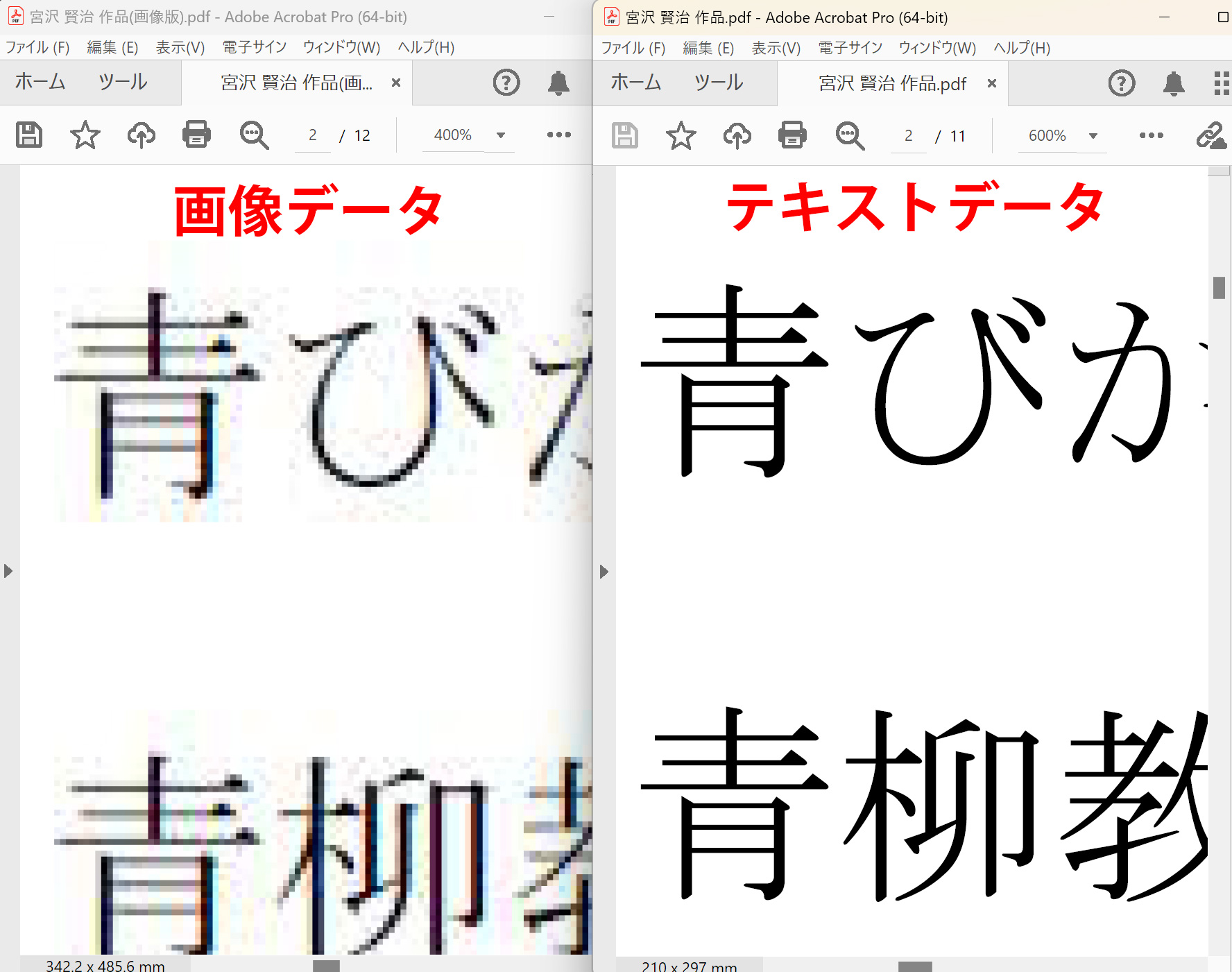
画像かテキストなのかを判断するには、PDFを拡大することで判断できます。それぞれ、50%→400%に拡大してみました。
左の画像データの方は「文字が荒れている」のに対し、右側のテキストデータの方は「文字がきれいに」表示されています。

単独で見てみると、画像データの方は文字がギサギサしており、色あせなどが見られます。

文字データは、文字の色あせもなく、輪郭もしっかりしています。
という訳で「スキャン画像か文字データか判断する方法」の結論としては、PDFを拡大し文字が「荒れる・汚くなったらスキャン画像データ」、「きれいなままならテキストデータ」という事になります。
見た目以外に画像データと文字データは何が違う?
PDFを拡大した時に違いが出ることは分かりましたが、その他にも違いがあります。
PDFのデータサイズが違う
画像データは、テキスト(文字)データと比べ、データ量が大きく画像データで保存されたPDFはデータサイズが大きくなる傾向があります。

例えば、この記事の一番上で紹介した、画像とテキストPDFの目次ページのみのそれぞれのPFDサイズです。
一番から順に「テキスト」「画像」「画像PDFも元になった画像JPEGファイル」の順のデータサイズ比較です。
テキストPDFは、約100kbで済んでますが、画像PDFは400kbの4倍のサイズ*になっています。
もちろん、画像データを圧縮率を高めたり、解像度を下げれば、データサイズを抑えることができますが、その分文字がにじむ・荒れます。
* 今はPCもネット回線も性能が良いので、この程度のデータ量の差は気にしなくて良いと思います。
スキャン画像で保存されたPDFの文章を検索・文字コピーするにはOCR処理が必要
画像で保存されたPFDは、そのままではパソコン側は文字(テキストデータ)として認識できず、文字で検索したり、文字をコピーしたり出来ません。
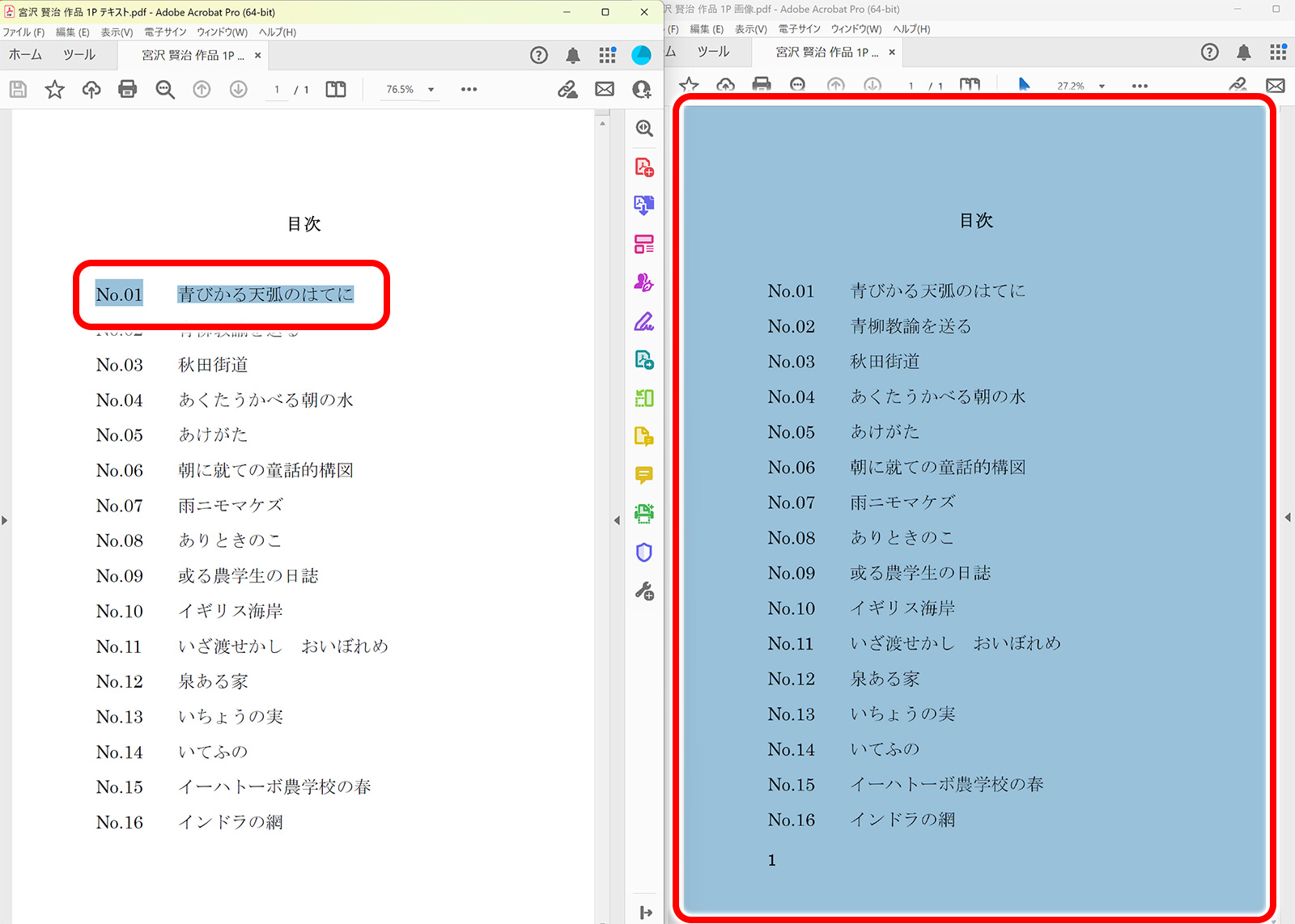
左はテキストデータのPDF。1文字ごとにコピーの範囲が選べる(文字がハイライト(青く囲われている)されている部分がコピー対象)。
右はスキャン画像データのPDF(OCR未処理)。1枚の画像なのでコピーしようとするとページ全体が選択されてしまいます。
そこで、画像に含まれる文字をテキストデータとしてコンピューターが認識できるようにするOCRという作業が必要になります。
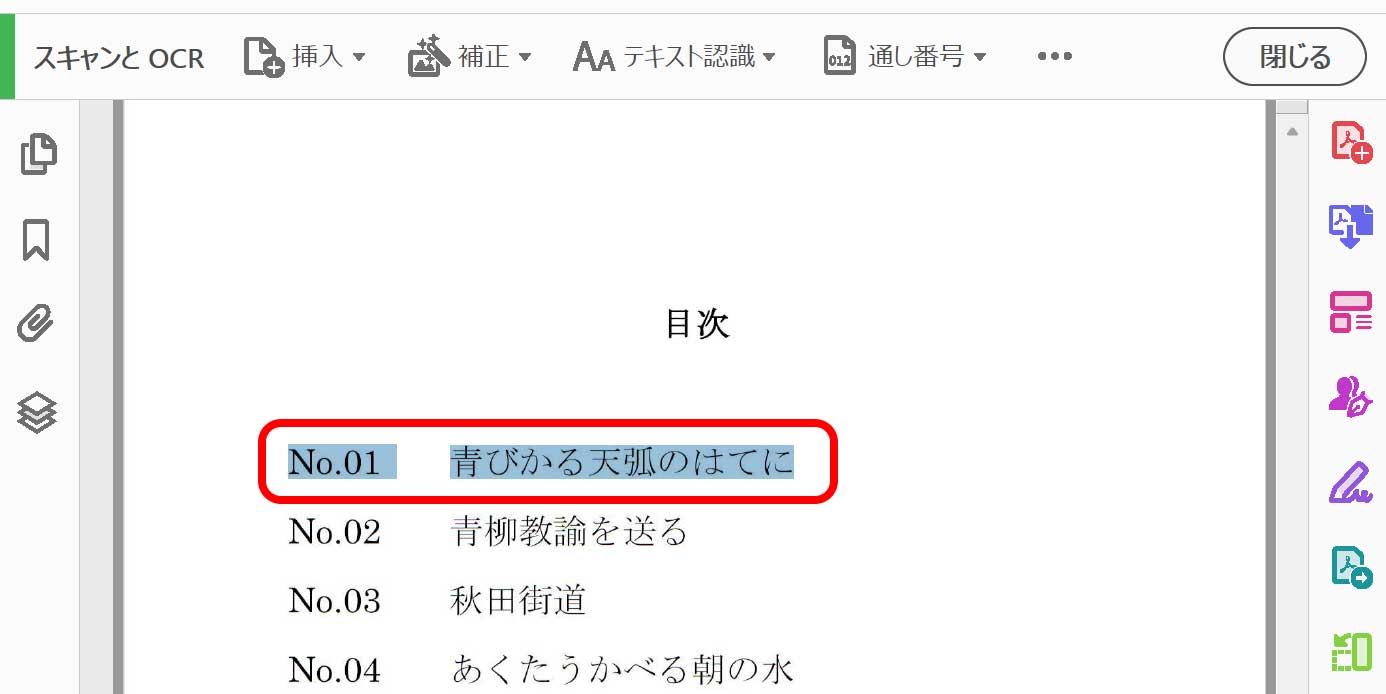
画像データの書類PDFをAcrobatのOCRでテキスト認識後に、テキストをなぞると、文字を一つずつコピーが出来るようになります。
PDFで文章を画像データで保存するメリットはないのに、なぜそのように作るのか
ここまで見てきて、文章を画像データでPDFに保存するメリットは殆どありません。なのに、なぜ画像形式のPDFが存在するのでしょうか。

それは、手元にプリント用紙しかなく、原本のWordなどデジタルデータが無い為、仕方なくプリントをスキャンしてPDFにしてからです。
考えられる理由は「昔の書類で、データが無く紙しか残っていない」、「セミナー等で貰ったプリント用紙しかない」などでしょうか。
という訳で、手元にあるPDFが、画像の文章なのかテキストデータの文章なのか調べる際の参考になれば幸いです。